DataStax Cassandra Backup Strategies
Author: Satish Rakhonde | 6 min read | January 4, 2024
The backup mechanism in Cassandra database takes a snapshot of all on-disk SSTable files. It actually creates the hard link of all existing SSTable files at the moment when the snapshot is taken.
Since it is just creating hard links, taking a snapshot is very fast (It would not take time to make a copy of SSTables). We can take a backup of all keyspaces, a single keyspace, or a single table without keeping the system offline.
We can recover to point-in-time by enabling incremental backups and taking a backup of commit logs on each node. However, it requires the last full snapshot prior to incremental backups.
Why Backup Despite Replication
Replication in Cassandra keeps copies of the replicated data at multiple locations, data centers, and zones. All operations performed in a cluster get replicated across all data centers and cloud zones.
We can easily recover lost data due to mistakenly dropped tables/ keyspace, an accidentally truncated table, or if any node goes down in a cluster. Because any dropped keyspace or any dropped or truncated table automatically creates a snapshot in data directory, assuming we have a full DDL of keyspace and its objects (tables, indexes), we can recover data easily. And if a node gets down/failed, there are Cassandra in-built utilities that can re-achieve consistency across clusters.
However, if the cluster’s data is corrupted, adverse events will be replicated to all other copies. In such cases, lost or uncorrupted data cannot be recovered without a backup.
Taking A Snapshot
There are two ways of taking a snapshot.
Using Nodetool Utility
Nodetool allows us to perform Cassandra backups at the node level. For Nodetool using a parallel SSH tool (such as pssh), we can snapshot a cluster, providing an eventually consistent backup. Although no single node is guaranteed to be consistent with its replica nodes at snapshot time, there are Cassandra in-built utilities that can help achieve cluster-wide consistency.
When we run a snapshot using nodetool, it first flushes all in-memory writes to the disk and makes a hard link of SST table files for each keyspace. We need to maintain enough disk space to allow snapshots. Since snapshots prevent obsolete files from being deleted, they can quickly cause disk space issues as they stack up. There should be a process in place for moving snapshots.
Run the nodetool snapshot command, specifying the hostname, JMX port, and keyspace.
For example:
$ nodetool -h localhost -p 7199 snapshot keyspace_name
It creates a snapshot (hard link of all sstables present at the time when the snapshot is taken) in the data directory for Cassandra.
For example: data_directory_location/keyspace_name/table_nameUUID/snapshots/snapshot_name
Advantages of Nodetool
We need not depend on the OpsCenter service to be up and running. And OpsCenter with Enterprise Edition only has features for backup/restore services.
Disadvantages of Nodetool
Nodetool requires parallel ssh utility to take a snapshot on each node at the same time to achieve consistency. While restoring the backups, manual effort or a script is required to copy backup files from the backup directory to data directory.
Note: It does not take a backup of the schema’s DDL.
Enabling Incremental Backups
When incremental backups are enabled (disabled by default), Cassandra hard-links each memtable-flushed SSTable to a backups directory under the keyspace data directory.
A snapshot at a point in time, plus all incremental backups and commit logs since that time, form a compete backup.
It gets stored under the data directory at the location mentioned below.
data_directory_location/keyspace_name/table_nameUUID/backups
Using OpsCenter for Backups
The enterprise edition of Cassandra has the option to backup using Opscenter. Using OpsCenter, we can schedule and manage backups, and restore from those backups, across all registered DSE clusters. It intelligently stores the backup data to prevent duplication of files.
Here are the steps to take a snapshot using OpsCenter:
- Go to the OpsCenter URL and then navigate to Services.

- Click on Configure on Backup Services.
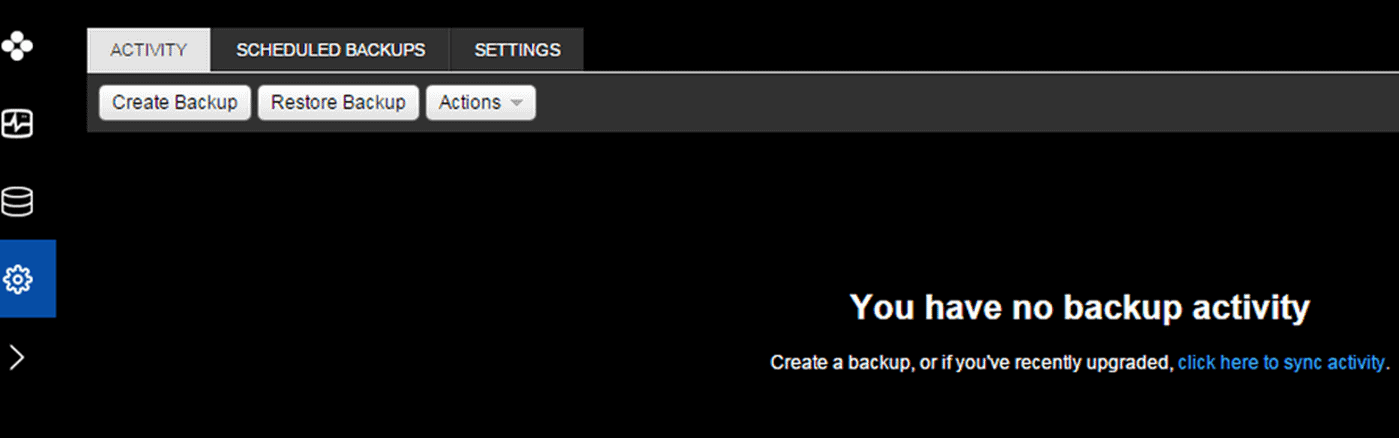
- We can either create an ad-hoc backup operation or schedule a proper backup.
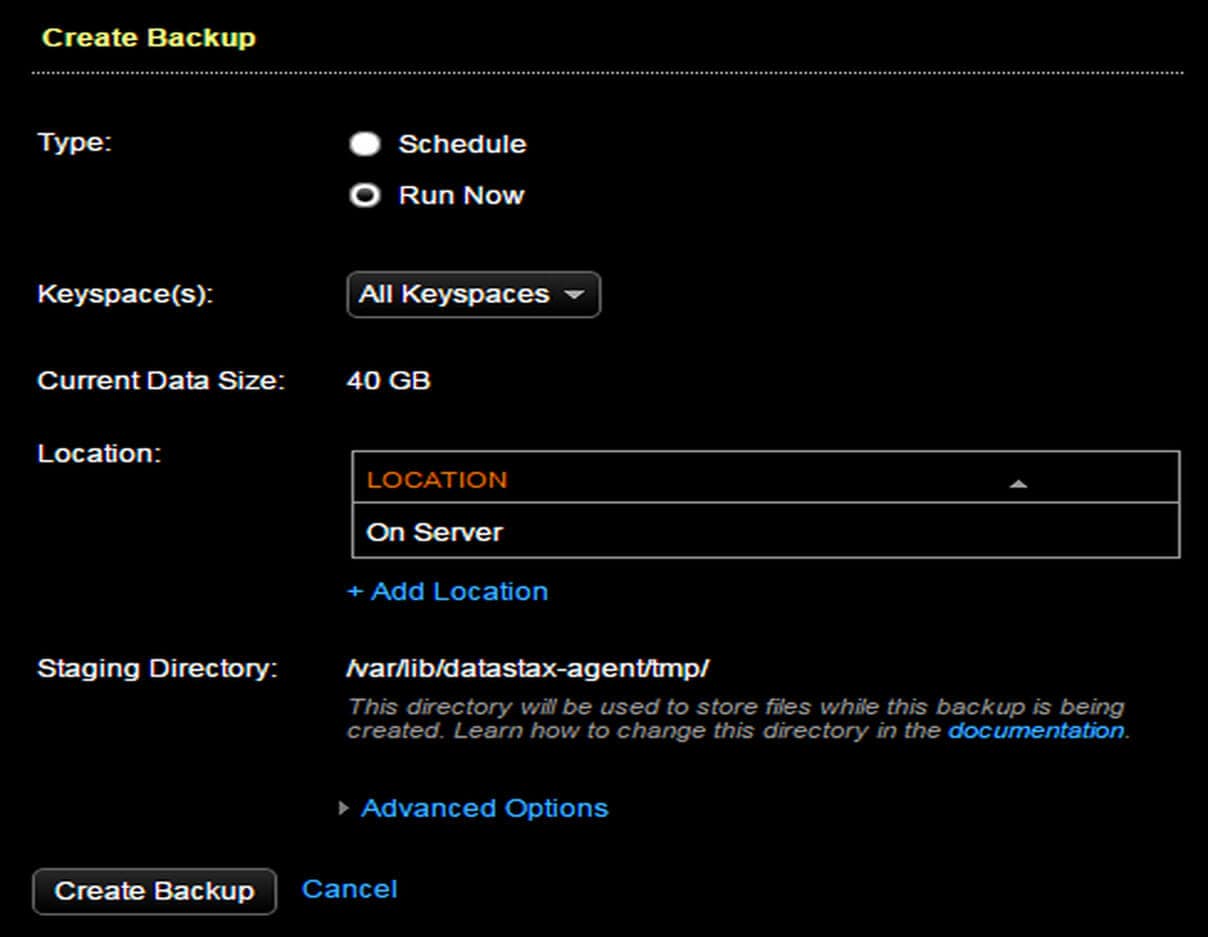
- Select Keyspaces for backup.
On completion, it would show something like this.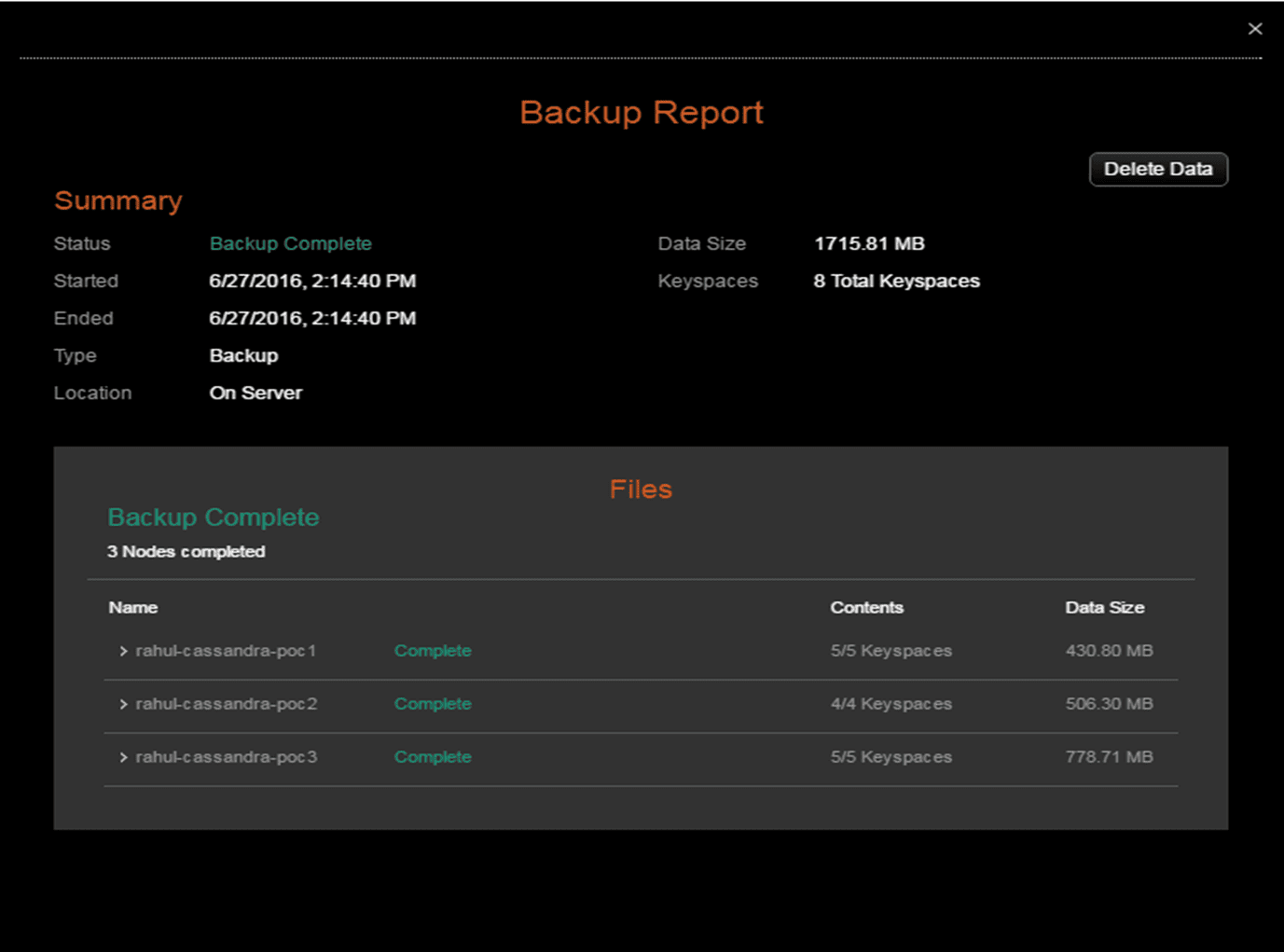
Advantages of OpsCenter
- We can schedule backups at the keyspace and/or table level and also backup commit logs too.
- Get notified when a job fails.
- OpsCenter takes backups to the local storage by default, but you can also specify another location, such as a S3 bucket.
- Backup compression and backup retention can be configured.
- We can perform full, table-level restorations quite easily. If commit logs are enabled, you can perform point-in-time restorations too.
- A full cluster clone is possible using OpsCenter, for example, clone a production cluster to a dev/test.
Disadvantages of OpsCenter
- Only the enterprise edition of OpsCenter provides backup/restore services.
- We have to make sure that this service remains up and running and can be accessible on the browser.
- It provides an option to store backups either on the server or in an Amazon S3 bucket only. We cannot configure it to use Google Cloud Storage.
Want to chat more about Cassandra with our expert team? Contact us to discuss innovating with Cassandra!
